‘Mona Lisa’ Comes to Life in Computer-Generated ‘Living Portrait’
A new artificial intelligence system can create realistic animations from a single static image
/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/filer/a8/87/a8871c6e-0b0f-4f62-b86e-8dfd3efee7b2/mona.gif)
The Harry Potter series got the world used to the idea of living portraits with its talking paintings and moving photographs. But last week, when an A.I.-generated “living portrait” of Leonardo da Vinci’s Mona Lisa began making the rounds on the web, many people were startled when the famous portrait moved her lips and looked around.
The animated portrait of Lisa Gherardini was one of several new “talking head models”—more commonly known as “deepfakes”—created by researchers from Samsung’s A.I. Center in Moscow and the Skolkovo Institute of Science and Technology. Using just a few frames of reference or even a single image, the researchers also made deepfakes of celebrities like Oprah, brought to life single snapshots of Marilyn Monroe and Albert Einstein, and created new expressions for famous images like Vermeer’s Girl with a Pearl Earring.
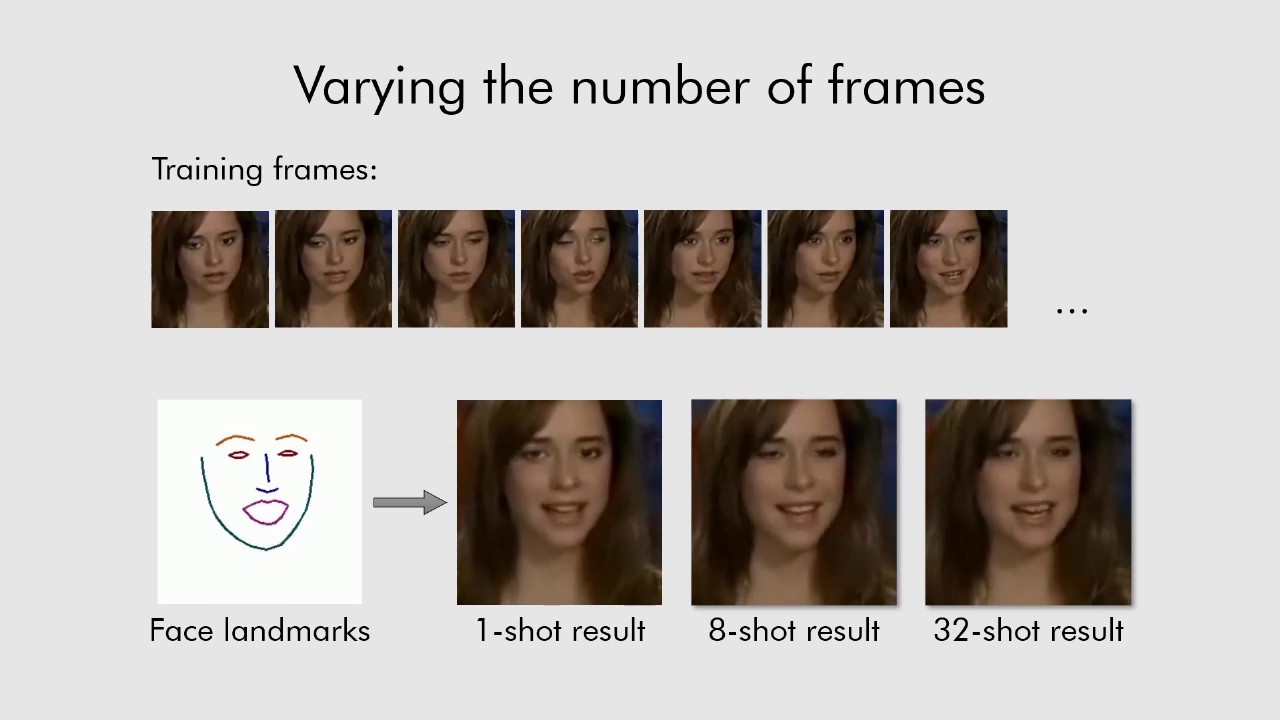
The researchers posted their method, which they call “few shot learning,” on YouTube and in a paper that has yet to be peer-reviewed on the preprint repository arXiv.org. While the details get pretty technical, Mindy Weisberger at LiveScience reports that to produce the living portraits a type of artificial intelligence called a convolutional neural network trains itself by analyzing reference images. It then applies the facial movements from a series of frames to a static image, like the Mona Lisa. The more angles and reference images it has, the better the living portrait becomes. According to the paper, the A.I. could produce “perfect realism” (measured by humans’ ability to discern which of three image sets were deepfakes) using just 32 reference images.
The Mona Lisa, of course, is just one image, so the three “living portraits” of Leonardo’s masterpiece are a bit unsettling. For the brief animations, the neural network observed three different training videos, and the three versions of Mona Lisa based on those frames each appear to have different personalities. If Leonardo had painted his famous model from different angles, the system could have produced an even more realistic living portrait.
While the animated Mona Lisa is entertaining, the rise of deepfakes has generated concern that the computer-generated likenesses could be used to defame people, stoke racial or political tensions and further erode trust in online media. “[T]hey undermine our trust in all videos, including those that are genuine,” writes John Villasenor at The Brookings Institution. “Truth itself becomes elusive, because we can no longer be sure of what is real and what is not.”
While A.I. is being used to create deepfakes, Villasenor says that, at least for now, it can also be used to identify deepfakes by looking for inconsistencies that aren’t apparent to the human eye.
Tim Hwang, director of the Harvard-MIT Ethics and Governance of AI Initiative, tells Gregory Barber at Wired that we’re not at the point where bad actors can create sophisticated deepfakes on their personal laptops just yet. “Nothing suggests to me that you’ll just turnkey use this for generating deepfakes at home,” he says. “Not in the short-term, medium-term, or even the long-term.”
That’s because using Samsung’s new system is expensive and requires expertise. But Barber’s article points out that it doesn’t take a super-sophisticated photo-realistic video made by a neural network to fool people. Just last week, a manipulated video that had been slowed down to make U.S. House Speaker Nancy Pelosi sound drunk circulated on social networks.
Eventually, however, the technology will be good enough that bad actors will be able to produce deepfakes so convincing they can’t be detected. When that day comes, Hwang tells Wired, people will need to rely on fact-checking and contextual clues to sort out what’s real and what’s fake. For instance, if Mona Lisa’s close-lipped half-smile becomes a toothy grin and she tries to sell you whitening toothpaste, it’s surely a deepfake.